비선형 모델 신경망

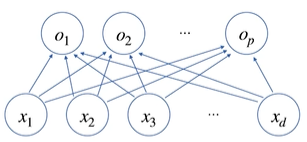
(그림) x→o는 하나의 선형 모델이다. $x_1$~$x_d$ 벡터를 $o_1$~$o_p$ 벡터로 만들기 위한 모델은 총 $d$x$p$ , 즉 weight matrix (W)의 차원과 같다. 즉 가중치 행렬은 각 화살표 변환의 집합이라 생각할 수 있다.
활성 함수 (activation function)
신경망은 선형 모델과 활성 함수(activation function)의 합성 함수이다.
$\sigma(W^{(l)} x +b^{(l)})$
활성 함수의 역할은 모델에 **비선형성(nonlinearity)**을 추가한다는 것이다.
비선형성이 필요한 이유
실제 해결하고자 하는 문제는 선형 모델로 풀리지 않는다. 만약 활성화 함수가 선형이라면 그저 신경망을 쌓는 것과 같은 효과일 것이다. 활성화 함수는 구분선이 비선형으로 변화하며 정교해지도록 하는 효과가 있으며, bias는 구분선의 위치를 조정하는 역할을 한다.
vanishing gradient 문제
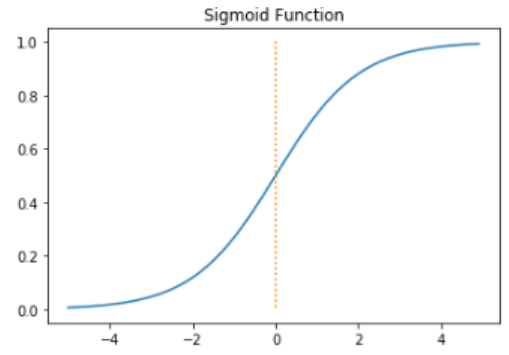
sigmoid 보다 ReLU가 더 자주 쓰이는 이유는 무엇일까?
이는 시그모이드가 양 방향으로 향하면서 기울기가 완만해지는데, 이 경우 미분값이 0에 가까워지며 backpropagation 과정에서 미분 값이 전달되지 않아, 학습에 어려움이 생기기 때문이다.
순전파 (Forward Propagation)
순차적인 신경망 계산으로, 학습을 하는 과정이 아닌, input이 들어올 때 output을 도출하는 계산과정을 의미한다.
층을 쌓는 이유
- 매개변수의 수가 줄어든다. 적은 매개변수로도 같은 효과를 낼 수 있다.
- 학습의 효율성 신경망을 깊게 하면 학습해야 할 문제를 계층적으로 분해할 수 있다. 그리고 이를 다음 레이어로 전달할 수 있으므로, 다음 레이어는 이전 레이어의 정보를 사용해 더 효과적인 학습을 할 수 있다.
역전파 (backpropagation)
학습은 파라미터 W(가중치)와 b(편향)을 찾는 것이다. chain rule을 통해 그라디언트 벡터를 전달하여 W를 업데이트한다.
자동 미분 (auto-differentiation)
pytorch에서 tensor는 이전 값을 추적하기 때문에 미분 계산이 가능하다. 메모리의 사용량이 늘어나게 된다.
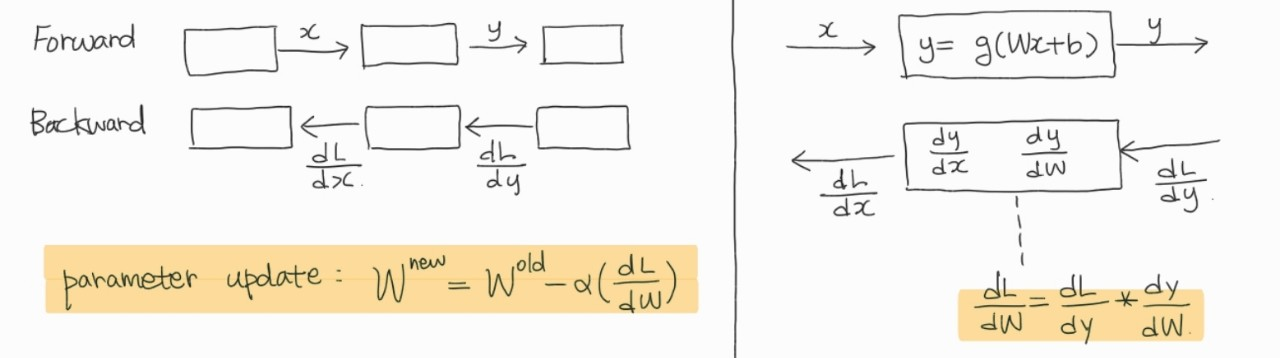
MLP(다중 퍼셉트론)은 은닉층의 출력 값에 대한 기준값을 정의할 수 없다. 이는 은닉층에서의 출력 값의 정답이 없다는 것이다. 이를 해결하기 위한 방법이 backpropagation이다. 역전파는 심층 신경망 내의 가중치와 편향이 그 오차에 얼마만큼 기여했는지 계산하여 파라미터를 업데이트한다.
→ y값에 대해 W편미분, x 편미분 하여 chain rule을 통해 W의 오차에 대한 기여도인, loss의 W편미분 값을 구할 수 있다.
'네이버 부스트캠프 AI tech 3기' 카테고리의 다른 글
| 5. CNN과 RNN (0) | 2022.01.25 |
|---|---|
| 4. 확률론, 베이즈 (0) | 2022.01.25 |
| 2. 경사하강법 (Gradient Descent) (0) | 2022.01.23 |
| 1. 벡터와 행렬 (0) | 2022.01.23 |
| 회고(1주차) (0) | 2022.01.23 |